Résoudre le cube-serpent en Python
27 Sep 2011
Je me suis amusé à écrire un petit programme en Python qui résout le cube-serpent (ainsi nous pouvons dire qu’un serpent en résout un autre).
Mon but était surtout d’apprendre le langage Python, avec un problème intéressant, pas trop compliqué (c’est de la force brute). Il m’a permis de découvrir différents aspects de Python.
EDIT : Je l’ai également implémenté en C.
L’algorithme proposé résout un cube-serpent généralisé. En effet, il sait trouver des solutions pour obtenir un cube de 3×3×3, mais également d’autres tailles, comme 2×2×2 ou 4×4×4. Il sait également résoudre des volumes non cubiques, comme 2×3×4. Et pour être totalement générique, il fonctionne pour un nombre quelconque de dimensions (2×2, 3×5×4×2, 2×3×2×2×4). Comme ça, vous saurez replier un serpent en hypercube…
Je vais d’abord présenter le problème et décrire l’algorithme de résolution et survoler l’implémentation, puis je vais m’attarder sur certaines fonctionnalités de Python qui m’ont semblé très intéressantes.
Résolution
Problème
Le but est de replier la structure du serpent pour qu’elle forme un volume, par exemple un cube.
La structure peut être vue comme une liste de vecteurs orthogonaux consécutifs, ayant chacun une norme (une longueur). Elle peut donc être caractérisée par la liste des normes de ces vecteurs. Ainsi, la structure du serpent présenté sur Wikipedia est la suivante :

[2, 1, 1, 2, 1, 2, 1, 1, 2, 2, 1, 1, 1, 2, 2, 2, 2]Le volume cible peut être représenté par un graphe, un ensemble de sommets reliés par des arêtes, auquel on ajoute la notion d’orientation dans l’espace (il est important de distinguer les arêtes orthogonales entre elles). En clair, chaque sommet représente une position dans le cube : il y a donc 27 sommets pour un cube 3×3×3.
L’objectif est de trouver dans le graphe ainsi formé par le cube un chemin hamiltonien (un chemin qui passe par tous les sommets une fois et une seule) qui respecte la contrainte de la structure du serpent.
Principe
Pour trouver les solutions, il suffit de partir d’un sommet et tenter de placer les vecteurs de la structure consécutivement un à un, en respectant trois contraintes :
- rester dans le volume (évidemment) ;
- le nième vecteur doit être orthogonal au (n-1)ième vecteur (cette règle ne s’applique pas pour le tout premier vecteur) ;
- le vecteur “placé” dans le cube ne doit pas passer par une position déjà occupée (physiquement, il n’est pas possible de faire passer une partie du serpent à travers une autre).
Il faut donc placer récursivement tous les vecteurs possibles, c’est-à-dire tous les vecteurs orthogonaux au précédent, qui ne sortent pas du cube et qui ne passent pas par une position déjà occupée. Jusqu’à arriver soit à une impossibilité (plus aucun vecteur ne respecte ces 3 contraintes), soit à une solution (tous les vecteurs sont placés).
Pour ne manquer aucune solution, il faut répéter cet algorithme en démarrant avec chacun des points de départ (donc les 27 sommets pour un cube 3×3×3).
Limites
Cet algorithme ne détecte pas les symétries ni les rotations, il donne alors plusieurs solutions “identiques”. Une amélioration serait de les détecter “au plus tôt” et de ne pas les construire.
EDIT : La version 0.2 gère les symétries et les rotations, pour éviter de calculer plusieurs solutions identiques. Plus d’explications dans ce commentaire et le suivant.
Implémentation
Voici une explication succincte des différentes parties du programme (pour plus d’informations, lire les commentaires dans le code).
Vector
Nous avons besoins de vecteurs, mais pas n’importe lesquels : seulement ceux qui ont une et une seule composante non-nulle, c’est-à-dire des multiples des vecteurs de la base. En effet, par exemple en 3 dimensions, la direction de chacun des vecteurs sera soit droite-gauche, soit dans haut-bas, soit avant-arrière, mais jamais en diagonale avant-droite vers arrière-gauche.
Ainsi, au lieu de stocker toutes les composantes, le Vector ne contient que la
valeur de la composante non-nulle ainsi que sa position (plus facile à
manipuler):
Vector(position, value)VolumeHelper
Cette classe définit l’outil que va utiliser le solveur pour noter tout ce qu’il fait : le chemin emprunté et les sommets déjà visités. À chaque fois qu’il place un vecteur dans le volume, il “allume les petites lumières” associées aux sommets visités, et quand il revient en arrière (pour chercher d’autres solutions), il éteint ces petites lumières (par lumières, comprenez booléens).
SymmetryHelper
Cette classe a été ajoutée dans la version 0.2. Elle définit l’outil que va utiliser le solveur pour n’explorer que les solutions nécessaires, en ignorant les symétries et les rotations.
Solver
Le solveur place récursivement les vecteurs de la structure dans toutes les
positions possibles (en s’aidant du VolumeHelper) afin de trouver toutes les
solutions.
Solutions
Lors de l’exécution du script, les solutions s’affichent au fur et à mesure :
$ ./snakesolver.py
([0, 0, 0], [2x, y, -x, 2z, y, -2z, x, z, -2y, -2x, y, -z, y, 2z, -2y, 2x, 2y])
([0, 0, 0], [2x, z, -x, 2y, z, -2y, x, y, -2z, -2x, z, -y, z, 2y, -2z, 2x, 2z])
([0, 0, 0], [2y, x, -y, 2z, x, -2z, y, z, -2x, -2y, x, -z, x, 2z, -2x, 2y, 2x])
...
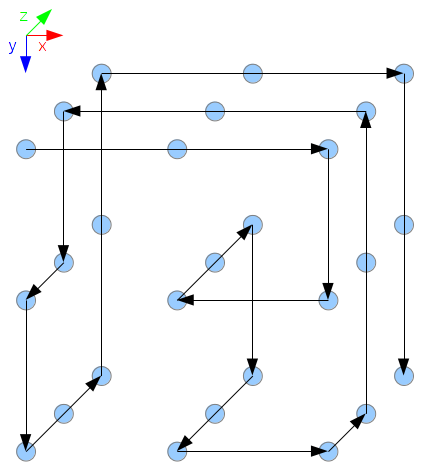
Considérons la première solution :
([0, 0, 0], [2x, y, -x, 2z, y, -2z, x, z, -2y, -2x, y, -z, y, 2z, -2y, 2x, 2y])
Le point de départ est [0, 0, 0]. On se déplace d’abord de 2 sur l’axe x,
puis de 1 sur l’axe y, de -1 sur l’axe x, etc.
Voici la représentation graphique de cette solution :
Fonctionnalités de Python
Maintenant, voici quelques éléments essentiels du langage Python dont je me suis servi pour ce programme.
Compréhension de liste
La compréhension de liste (ou liste en compréhension) est très pratique. Je l’ai utilisée plusieurs fois dans l’algorithme. Je vais détailler deux exemples.
D’abord, dans la classe VolumeHelper :
def all_points(self, index=0):
if index == len(self.dimensions):
return [[]]
return ([h] + t for h in xrange(self.dimensions[index])
for t in self.all_points(index + 1))Ce qui est retourné à la fin signifie :
tous les éléments de la forme
[h] + t(l’élémenthen tête de liste suivie de la queue de la liste) pourhcompris entre0etself.dimensions[index](un entier) et pour touttcompris dans les résultats de l’appel récursif
Ça ne vous éclaire pas ? Dit plus simplement :
le résultat de la concaténation de chacun des nombres de
0àn(avecn = self.dimensions[index]) à chacune des listes fournies par l’appel récursif
En fait, cette fonction fournit tous les points possibles pour les dimensions
données. Par exemple, si dimensions = [2, 2], alors le résultat sera :
[[0, 0], [0, 1], [1, 0], [1, 1]]Pour dimensions = [2, 2, 3], le résultat sera :
[[0, 0, 0], [0, 0, 1], [0, 0, 2], [0, 1, 0], [0, 1, 1], [0, 1, 2], [1, 0, 0],
[1, 0, 1], [1, 0, 2], [1, 1, 0], [1, 1, 1], [1, 1, 2]]Sans compréhension de liste, il serait difficile d’écrire le corps de cette fonction en 3 lignes !
Remarque : la compréhension de liste retourne une liste si elle est définie
entre [], alors qu’elle retourne un générateur (un _itérateur) si elle
est définie entre ()._
Second exemple, dans Solver.__solve_rec(…) :
for possible_vector in ( Vector(i, v)
for v in [ norm, -norm ]
for i in xrange(len(self.dimensions))
if i != previous_position ):Cette partie fournit un ensemble de Vector(i, v), pour toutes les combinaisons
de i et de v dans leurs domaines respectifs, qui vérifient la condition (qui
ici ne porte que sur i).
En clair, ici nous récupérons tous les vecteurs possibles, c’est-à-dire orthogonaux au précédent et avec la norme (la longueur) imposée par la structure.
Itérateur
La notion d’itérateur est présente dans beaucoup d’autres
langages. Un itérateur retourne un nouvel élément à chaque appel à la
méthode next(). En pratique, il est souvent utilisé de manière transparente
dans une boucle for _variable_ in _iterator_ :
for i in xrange(10):
print ixrange(…) retourne un itérateur et fournit les valeurs au fur et à
mesure, alors que range(…) crée la liste de toutes les valeurs, qui
est ensuite parcourue.
Yield
Les expressions yield permettent de créer un itérateur très simplement.
Pour résoudre le cube-serpent, il est préférable d’une part de fournir les solutions au fur et à mesure qu’elles sont trouvées, et d’autre part de pouvoir ne calculer que les k premières solutions.
La première contrainte est souvent résolue grâce à des callbacks : la fonction de calcul prend en paramètre une fonction, qui sera appelée à chaque résultat trouvé, le passant alors en paramètre.
La seconde est plus délicate : elle implique que l’algorithme s’arrête dès qu’il
trouve une solution, et que lors d’un prochain appel il reprenne le calcul là où
il s’était arrêté, afin calculer les solutions suivantes. Cela nécessite de
conserver un état. Pour un itérateur simple comme celui d’une liste, il suffit
de stocker l’index courant de parcours, et de l’incrémenter à chaque appel à
next(). Gérer manuellement l’itération sur les solutions du cube-serpent
semble beaucoup plus complexe, d’autant plus que les solutions sont trouvées
dans des appels récursifs.
C’est là qu’interviennent les expressions yield, qui répondent aux deux
besoins en même temps. Utiliser une expression yield dans le corps d’une
fonction suffit à transformer cette fonction en un générateur. Il n’est donc
plus possible de retourner de valeur grâce à return.
Dès que l’expression yield est rencontrée, la valeur est transmise et l’exécution de la fonction s’arrête. Elle reprendra lors du prochain appel.
Afin d’utiliser ce principe pour la génération des solutions, les fonctions
SnakeCubeSolver.solve() et SnakeCubeSolver.__solve_rec(…) ne sont donc pas
des fonctions ordinaires, mais des générateurs :
if step == len(self.structure):
yield init_cursor, self.volume_helper.path[:]Grâce à cette implémentation, il est possible de parcourir toutes les solutions :
for solution in solver.solve():
print solutionou alors de ne générer que les k premières :
max_solutions = 5
solutions = solver.solve()
for i in xrange(max_solutions):
try:
print solutions.next()
except StopIteration:
breakLambdas
Python supporte aussi les expressions lambda, issues du lambda-calcul, qui permettent d’écrire des fonctions anonymes simplement.
J’utilise cette fonctionnalité une fois dans le programme :
needed_length = reduce(lambda x, y: x * y, self.dimensions) - 1Il s’agit de la déclaration d’une fonction avec deux arguments, qui retourne leur produit.
La fonction reduce(function, iterable, …) permet d’appliquer
cumulativement la fonction aux éléments de l’iterable, de gauche à droite, de
manière à réduire l’iterable en une seule valeur.
Même si “ce qui se conçoit bien s’énonce clairement”, la fonction
reduce est bien plus facile à comprendre qu’à expliquer en quelques mots…
Ici, donc, needed_length contient le produit de tous les éléments de la liste
self.dimensions.
Conclusion
La résolution du cube-serpent est intéressante, tout comme sa généralisation à n’importe quel volume de dimensions quelconque. Je me suis arrêté là (EDIT : finalement, non), mais la détection des symétries et des rotations “au plus tôt” serait une amélioration non négligeable (et pas si évidente).
Débutant tout juste en Python, ce micro-projet m’a permis de beaucoup apprendre, et de découvrir quelques bonnes surprises comme les expressions yield que je ne connaissais pas.
J’espère que ça vous a amusé aussi.
Script
Le code source est disponible sur ce dépôt git : snakesolver.
Hello,
Sympa ton challenge perso :)
Pour info, un 3x3x3, tu le résous en combien de temps ?
Par ailleurs, tu connais la complexité de ton algo ?